Comparativa Técnica: Docker Model Runner vs. Ollama
1. Comparación técnica detallada: Docker Model Runner vs Ollama
Arquitectura: Docker Model Runner es una funcionalidad integrada en Docker Desktop (a partir de la versión 4.40) que trata a los modelos de IA como artefactos nativos de Docker. No ejecuta el modelo dentro de un contenedor, sino mediante un servidor de inferencia nativo en el host (basado en llama.cpp). Esto permite acceso directo a GPU (Metal/MPS en Mac) sin la sobrecarga de virtualización. Los modelos se empaquetan y distribuyen como artefactos OCI (es decir, similares a imágenes Docker en Docker Hub) con etiquetas versionadas, lo que facilita su integración en pipelines existentes (registro, versionado, etc.). Ollama, por otro lado, es una herramienta independiente (open source) diseñada específicamente para ejecutar LLMs localmente. Funciona como un servicio local que utiliza también la librería llama.cpp u otras backend de inferencia, pero fuera del ecosistema Docker. Ollama proporciona un binario/daemon multiplataforma que incluye un servidor API y CLI propios para gestionar modelos (descarga, ejecución, etc.) y sí corre directamente sobre el host (o en un contenedor opcionalmente) con su propio runtime.
Compatibilidad de plataformas: Actualmente Docker Model Runner está en beta y solo es compatible con macOS en hardware Apple Silicon (M1, M2, M3, M4). Se espera soporte para Windows con GPU NVIDIA en 2025 (Docker Desktop para Windows). En macOS, Model Runner aprovecha Metal Performance Shaders para aceleración GPU. En Linux aún no está disponible (al menos al momento actual). En contraste, Ollama es multiplataforma: ofrece instaladores nativos para macOS (Apple Silicon e Intel), Linux y Windows. Ollama en macOS también puede usar la GPU de Apple Silicon vía llama.cpp (MPS), y en Windows/Linux puede usar CPU o GPUs compatibles (por ejemplo, NVIDIA CUDA si se compila con soporte, aunque la aceleración en Windows puede requerir WSL o no ser tan directa). Es decir, Ollama brinda mayor cobertura de entornos fuera de Mac, mientras que Model Runner se enfoca por ahora en Macs con Docker.
Rendimiento: Ambos buscan maximizar el rendimiento local al evitar llamadas remotas. Docker Model Runner ejecuta la inferencia en el host, con acceso directo a la GPU de Apple Silicon, eliminando la latencia de red y permitiendo cargas rápidas (los modelos se cargan en memoria bajo demanda y se descargan cuando no se usan). Esto resulta en tiempos de respuesta muy bajos y la posibilidad de iterar rápidamente durante el desarrollo. Ollama igualmente ejecuta los modelos localmente y puede aprovechar aceleración (en Mac, MPS; en sistemas con CUDA, en teoría se puede compilar soporte GPU). En pruebas informales, ambos pueden lograr rendimientos similares al usar llama.cpp como backend; sin embargo, si Ollama se ejecuta dentro de un contenedor Docker en Mac, no podrá usar la GPU de Apple debido a limitaciones de virtualización. La recomendación de Ollama es ejecutarlo directamente en el host para aprovechar la GPU en Mac. En Windows con GPU NVIDIA, es de esperar que Model Runner (cuando esté disponible) tenga rendimiento nativo vía CUDA, mientras que Ollama actualmente en Windows podría estar limitado a CPU (o a usar su imagen Docker con WSL2 + NVIDIA, pero es complejo). En cuanto a uso de memoria, Model Runner maneja los modelos de forma eficiente: los descarga una vez (persisten en cache local) y solo los carga en RAM al usarlos. Ollama también mantiene un cache local de modelos descargados en ~/.ollama y carga en memoria según uso; ambos soportan modelos cuantizados para reducir requerimientos. En resumen, en macOS ambos ofrecen inferencia rápida sin latencia de red, pero Model Runner brinda una integración más optimizada con GPU en Docker Desktop, mientras que Ollama requiere ejecución nativa (fuera de Docker) para rendimiento óptimo en Apple Silicon.
Facilidad de uso: Docker Model Runner se integra al flujo de trabajo Docker, lo cual es ventajoso para desarrolladores familiarizados con Docker. Se administra con comandos familiares (docker model pull/run/list/...) sin necesitar nuevas herramientas. Por ejemplo, gestionar un modelo es tan simple como gestionar una imagen: docker model pull ai/mi-modelo para descargar, docker model run ai/mi-modelo "prompt" para ejecutar inferencia, etc. Esto reduce la curva de aprendizaje si ya se conoce . Además, expone endpoints compatibles con la API de OpenAI para integrar en aplicaciones de forma estándar (como veremos más adelante). Por otro lado, Ollama ofrece su propio CLI (ollama run, ollama pull, etc.) y un servidor local. Su instalación es sencilla (un único paquete) y no requiere Docker. Para alguien no acostumbrado a Docker, Ollama puede resultar más simple ya que es “instalar y usar”. Ollama también tiene una librería de modelos preconfigurados que se pueden instalar con comandos simples (ej. ollama run llama2 descarga y lanza LLaMA 2 automáticamente). En resumen: si ya usas Docker diariamente, Model Runner se sentirá muy natural; si prefieres una herramienta dedicada y standalone, Ollama puede parecer más directa. Ambos son fáciles de usar, pero en contextos distintos.
Integración y casos de uso ideales: Docker Model Runner brilla en entornos de desarrollo containerizados y flujos DevOps. Por ejemplo, en una aplicación compuesta por múltiples servicios Docker, se puede usar Model Runner para añadir un servicio de IA local sin montar infra adicional: las aplicaciones dentro de contenedores pueden llamar al endpoint interno de Model Runner y así tener capacidades de IA localmente. Esto facilita pruebas de aplicaciones con LLM en CI/CD, manteniendo privacidad (datos y prompts no salen del entorno) y evitando costos de API. Además, el hecho de distribuir modelos como OCI en registries permite a los equipos versionar y empaquetar modelos en pipelines CI/CD igual que cualquier artefacto. Un caso de uso ideal de Model Runner es en empresas que quieran prototipar con LLMs incorporados en sus aplicaciones, usando infraestructura local con Docker Compose o Kubernetes (futuro) y necesitando reproducibilidad (mismo modelo, misma versión en todos lados). También es ideal para desarrolladores front-end/back-end que quieren consumir un endpoint local tipo OpenAI sin depender de la nube. Por su parte, Ollama es ideal para experimentos locales rápidos, usuarios individuales y escenarios offline en cualquier OS. Un desarrollador que desea probar distintos modelos open-source localmente, comparar respuestas o interactuar vía línea de comandos, encontrará en Ollama una herramienta sencilla (por ejemplo, para rol-play, asistentes de código, chat con datos locales, etc., como comenta la comunidad). También se adapta a integrar en aplicaciones mediante su API HTTP (localhost:11434/api/generate), aunque esa API es propia de Ollama. Ollama es apropiado para escenarios donde Docker no está presente o no se desea configurar (por ejemplo, en una estación de trabajo Linux sin entorno Docker, o para usuarios menos familiarizados con contenedores).

2. Guía paso a paso: Uso de Docker Model Runner en macOS (Apple Silicon)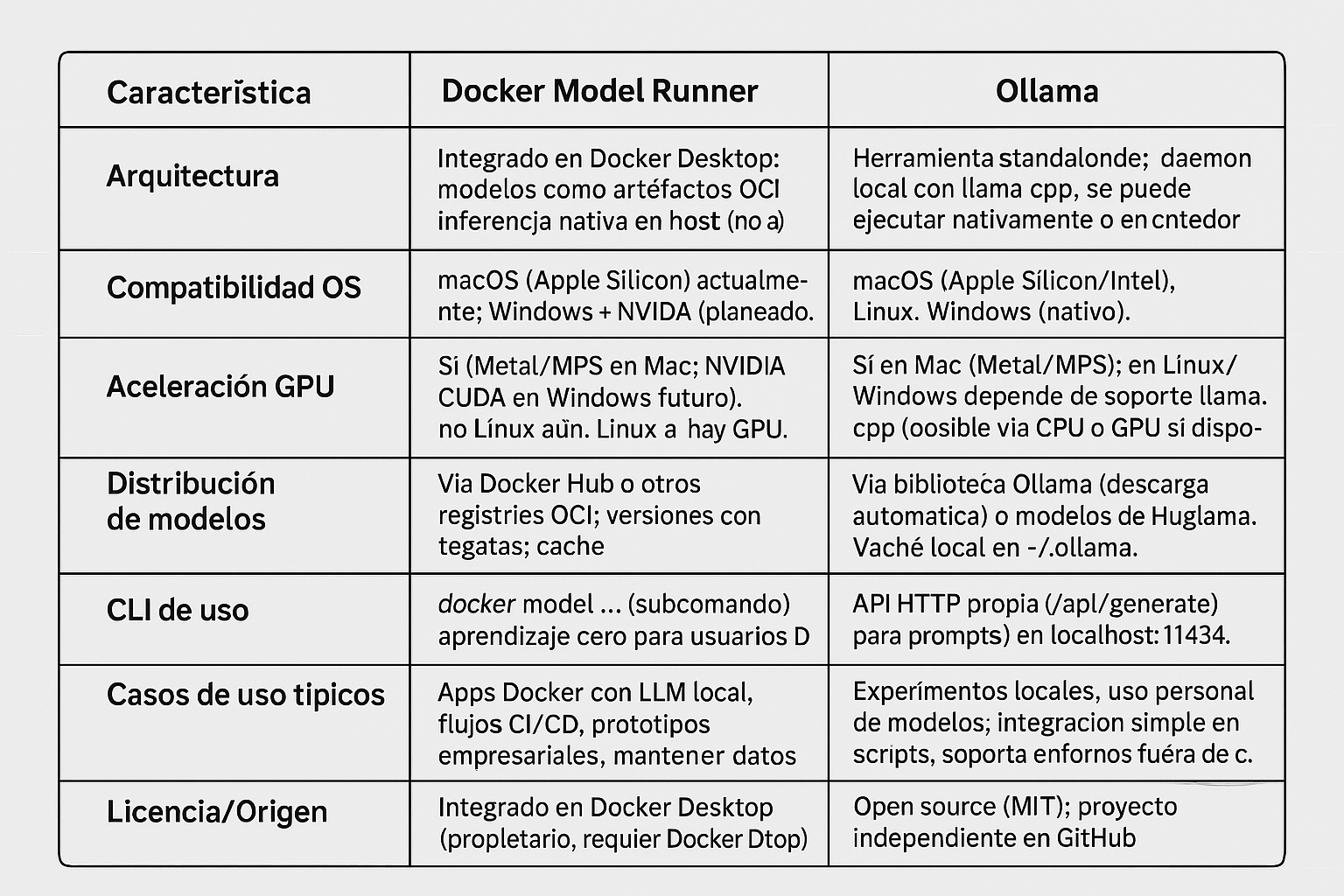
A continuación, se presenta una guía para comenzar a usar Docker Model Runner en macOS con Apple Silicon:
Paso 1: Instalar/actualizar Docker Desktop – Asegúrese de tener Docker Desktop 4.40 o superior instalado en su Mac con chip Apple Silicon. Docker Model Runner es un componente de Docker Desktop, por lo que no se instala por separado. Tras la instalación, verifique en Preferences -> Features que “Model Runner” esté habilitado (debería estarlo por defecto).
Paso 2: Verificar la disponibilidad del CLI – Abra una terminal y ejecute:
$ docker model status
Este comando comprueba si el servicio de Model Runner está activo. Debería obtener un estado "Running" indicando que Docker Desktop tiene la función habilitada. También puede listar la ayuda general con docker model help para ver los subcomandos disponibles (por ejemplo: list, pull, run, rm, etc.).
Paso 3: Listar y descargar modelos – Para ver qué modelos tiene localmente, use docker model list (inicialmente puede que ninguno, o los que ya haya descargado). Los modelos disponibles para descarga se encuentran en el Docker Hub, bajo el namespace ai (lista completa en hub.docker.com/u/ai). Por ejemplo, hay modelos como ai/llama3.2, ai/gemma3, ai/mistral, ai/phi4, ai/qwen2.5, entre otros. Para descargar un modelo, utilice docker model pull. Por ejemplo, descarguemos un modelo pequeño de prueba:
$ docker model pull ai/smollm2:latest
(Este comando descargará el modelo SmolLM 2, un modelo compacto de ejemplo, desde Docker Hub.) La primera vez, la descarga puede demorar pues algunos modelos pesan varios GB. Tras completarse, verá un mensaje de éxito. Puede repetir este paso con cualquier otro modelo disponible, por ejemplo: docker model pull ai/llama3.2:1B-Q8_0 para un modelo LLaMA 3.2 de ~1B parámetros cuantizado en int8.
Paso 4: Ejecutar un modelo localmente – Una vez descargado, podemos ejecutar inferencia con el modelo usando docker model run. Hay dos modos:
- Modo interactivo (chat): Si ejecuta docker model run ai/<modelo> sin argumentos, entrará en un REPL interactivo estilo chat con el modelo, donde puede escribir mensajes consecutivamente.
- Modo prompt único: Pasando una cadena al comando, ejecuta el modelo con ese prompt y muestra la respuesta y termina.
Por ejemplo, probemos un prompt simple en español con el modelo descargado (supondremos ai/llama3.2):
$ docker model run ai/llama3.2:1B-Q8_0 "Hola, ¿puedes explicar brevemente qué es Docker?"
El modelo procesará la solicitud y debería imprimir una respuesta en texto. Ejemplo de salida: "Docker es una plataforma de código abierto que permite empaquetar aplicaciones en contenedores, facilitando su despliegue y escalabilidad..." (la respuesta exacta variará según el modelo). Este comando muestra la capacidad de correr un modelo localmente para cualquier prompt dado. Puede experimentar con preguntas adicionales. Si ingresó al modo interactivo, puede salir con Ctrl+C o escribiendo el comando especial (por ejemplo, /bye).
Paso 5: Uso desde línea de comandos y entorno OpenAI – Ya vimos el uso básico mediante CLI. Docker Model Runner también expone una API compatible con OpenAI para que las aplicaciones puedan consumir el modelo local como si fuera un servicio OpenAI. Por defecto, dentro del contexto Docker, el endpoint está disponible en la URL http://model-runner.docker.internal/ (un hostname interno resolvible desde contenedores Docker). Los endpoints disponibles incluyen rutas análogas a la API de OpenAI, por ejemplo:
- POST /v1/chat/completions – para chat con mensajes (conversaciones).
- POST /v1/completions – para completar prompts simples.
- POST /v1/embeddings – para generar embeddings vectoriales.
Para utilizarlos, se debe especificar en el JSON el nombre del modelo (por ej. "model": "ai/llama3.2"). Un ejemplo usando curl desde dentro de un contenedor podría ser:
curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "ai/llama3.2", "messages": [ {"role": "user", "content": "¿En qué año fue fundada Roma?"} ] }'
Este POST devolverá un JSON con la respuesta del modelo como lo haría la API de OpenAI. Note que aquí usamos la ruta /engines/llama.cpp/v1/... que es aceptada; también es posible usar directamente /v1/chat/completions (el prefijo de engine es opcional).
Paso 6: Exponer el endpoint al host (opcional) – De forma predeterminada, las aplicaciones en contenedores pueden usar la URL interna anterior. Si desea acceder al servicio desde el host (por ejemplo, desde una aplicación local no contenedorizada, o para pruebas con cURL desde la Mac host), Docker Desktop ofrece una opción para habilitar un socket TCP. En la configuración de Docker Desktop -> Model Runner, habilite "Enable host-side TCP support" y tome nota del puerto asignado (por defecto 12434). Una vez activado, el servicio estará disponible en http://localhost:12434 con las mismas rutas API. Asegúrese de actualizar las configuraciones de su aplicación para apuntar a http://localhost:12434/v1/chat/completions (u otra ruta) en lugar del endpoint de OpenAI. Puede requerir también una clave API: Model Runner por defecto acepta cualquier valor de Authorization: Bearer <token> o ninguno, pero se puede establecer una clave fija vía variable de entorno API_KEY para mayor control (como se ve en la sección siguiente).
Con estos pasos, Docker Model Runner estará operando en su Mac y listo para responder a solicitudes, ya sea vía CLI interactiva o mediante APIs OpenAI-like. Todo el procesamiento ocurre localmente, preservando la privacidad de los datos y sin incurrir en costes por token. Además, gracias a la aceleración de Apple Silicon, incluso modelos de ~7B parámetros pueden correr con fluidez en un MacBook moderno.
3. Integración de Docker Model Runner en flujos CI/CD y proyectos con Docker Compose
Una ventaja clave de Docker Model Runner es su fácil integración en proyectos containerizados y flujos de desarrollo colaborativo. A continuación, veremos cómo integrarlo en un proyecto reproducible (por ejemplo, con Docker Compose) y consideraciones para CI/CD.
Configuración en Docker Compose: Supongamos que tenemos una aplicación web que queremos que use un LLM local. Podemos estructurar el proyecto con Docker Compose, teniendo servicios como frontend, backend, etc., y en lugar de añadir un contenedor separado para el modelo, aprovecharemos el Model Runner ya presente en Docker Desktop. La integración se logra mediante la comunicación a través de la red de Docker. Por ejemplo, nuestro backend podría tener en su configuración una URL base apuntando a Model Runner. Podríamos usar un archivo de entorno (por ejemplo backend.env) con el contenido:
# backend.env BASE_URL=http://model-runner.docker.internal/engines/llama.cpp/v1/ MODEL=ai/llama3.2:1B-Q8_0 API_KEY=${API_KEY:-modelrunner}
En este ejemplo, BASE_URL configura la URL interna de Model Runner (usando la ruta OpenAI-compatible), MODEL indica qué modelo usar por defecto (podría ser utilizado por el código de la app) y API_KEY define una clave de API que la app espera (aquí usamos un valor por defecto “modelrunner”). Luego, en el docker-compose.yml incluiríamos este archivo de entorno en el servicio apropiado, por ejemplo:
services: backend: build: ./backend env_file: backend.env # ... otras configuraciones (puertos, etc.)
Dentro del código de la aplicación (backend), se puede usar estas variables para formar las solicitudes al endpoint. Si la aplicación usa una librería de cliente OpenAI, bastaría con configurar la URL del endpoint OpenAI a BASE_URL y la clave de API a API_KEY para redirigir las peticiones al modelo local.
Ejecutar la aplicación con el modelo local: Iniciar todo es tan sencillo como siempre:
$ docker compose up -d
Esto levantará los contenedores de la app. El backend, al arrancar, sabrá (por las vars de entorno) que debe conectarse a model-runner.docker.internal. Cuando el backend envíe una petición de, por ejemplo, completar un prompt, esta llegará al Model Runner y obtendrá la respuesta del LLM local. Desde el punto de vista del desarrollador, no hubo necesidad de configurar un servidor de IA separado – Docker Model Runner actúa como parte de la plataforma Docker.
Mejores prácticas para CI/CD: En un entorno de integración continua, es posible que queramos ejecutar pruebas que involucren el modelo local. Para esto, la máquina runner de CI debería tener Docker Desktop (con Model Runner) disponible o, una vez que haya versión Linux, algún servicio equivalente. Algunas recomendaciones:
- Evitar descargar modelos pesados en cada ejecución: dado que los modelos pueden ser grandes, conviene aprovechar caching. Por ejemplo, en GitHub Actions en macOS runners, podríamos cachear el directorio ~/Library/Group Containers/group.com.docker/modelrunner donde Docker Desktop almacena los modelos descargados. Alternativamente, en un pipeline, ejecutar docker model pull ai/mi-modelo:tag antes de los tests y mantener un volumen/cache entre jobs para reutilizar esa descarga.
- Versionar el modelo usado: igual que se fijan versiones de imágenes, use etiquetas de modelo específicas (p.ej. ai/phi4:latest o mejor una versión concreta si está disponible) para garantizar reproducibilidad. Docker Model Runner soporta esto mediante los tags OCI (incluso digest SHA si se desea máxima precisión).
- Pruebas deterministas: Tenga en cuenta que los modelos generativos pueden producir salidas variables. Si se van a incorporar en pruebas automáticas, quizá fijar parámetros como temperatura=0 (determinismo) o emplear prompts fijos esperando ciertas respuestas. Esto escapa a Docker Model Runner en sí, pero es relevante para CI.
- Seguridad: En entornos de CI, las peticiones al socket Docker (para usar Model Runner) deben considerarse privilegiadas. En lugar de exponer el socket ampliamente, confine las pruebas que llaman al modelo dentro de contenedores controlados. Docker Model Runner requiere acceso al socket Docker para funcionar desde fuera (vía /var/run/docker.sock), lo cual en entornos Linux podría suponer configurar permisos. Sin embargo, dentro de Docker Desktop (Mac/Windows) esto está manejado internamente.
- Despliegues: Actualmente, Docker Model Runner no existe en servidores Linux, por lo que en despliegues productivos on-premise se tendría que usar otra estrategia (quizá un contenedor con ollama/ollama o similares). No obstante, para entornos de desarrollo y CI locales, Model Runner es excelente para acercar mucho la paridad con producción (ejecutando modelos open-source localmente en lugar de llamar a un servicio externo).
Ejemplo de flujo CI con Docker Compose: Imaginemos que tenemos pruebas end-to-end que levantan la aplicación con docker compose. Podemos agregar en la configuración de CI un paso que ejecute docker compose up -d en un runner Mac (con Docker Desktop) – esto automáticamente activa el Model Runner. La app se comportará como en local, usando el modelo. Luego corremos los test. Al finalizar, podemos hacer docker compose down y opcionalmente limpiar el modelo con docker model rm <modelo> para liberar espacio (aunque normalmente no es necesario si vamos a seguir usándolo).
En suma, Docker Model Runner se integra de forma transparente en proyectos Docker. No añade nuevos contenedores, sino que extiende las capacidades de Docker Engine para servir modelos de IA. Esto permite que un equipo incluya en su repositorio de código tanto el Dockerfile de su app como las referencias al modelo que debe usar, garantizando que cualquiera que clone el repo y tenga Docker Desktop adecuado pueda levantar la solución completa (app + IA) sin pasos adicionales de instalación de entornos ML. La familiaridad de Docker Compose y la unificación de entorno (app y modelo corriendo juntos en Docker) agilizan la colaboración y reducen la complejidad de manejar servicios de IA por separado.
4. Soporte de modelos específicos en Docker Model Runner (LLaMA, Phi, Mistral, Gemma, Qwen)
Docker Model Runner soporta varios modelos populares de la nueva generación de LLMs de código abierto, incluyendo las familias LLaMA (Meta), Phi (Microsoft), Mistral (Mistral AI), Gemma (Google) y Qwen (Alibaba). Todos estos modelos están disponibles para descarga bajo el namespace ai en Docker Hub. A continuación detallamos cada uno, indicando sus ventajas técnicas, requisitos y casos de uso:
-
LLaMA (Llama 3.x de Meta): Meta AI ha lanzado iteraciones de su modelo LLaMA hasta la versión 3. LLaMA 3.2 (y 3.3) son modelos orientados a instrucciones con tamaños relativamente pequeños (1B, 3B parámetros en las versiones disponibles en Model Runner) enfocados en ser ejecutados en dispositivos de menor potencia (edge). Ventajas: Son multi-idioma (soportan inglés, español, francés, alemán, etc.), tienen variantes de alta ventana de contexto (hasta 128k tokens en versiones completas) pero con cuantizaciones reducidas se pueden usar 8k tokens con muy poca memoria. Por ejemplo, LLaMA 3.2 1B Q8_0 ocupa ~1.2 GB de VRAM, apto para Mac con 8-16 GB de RAM, mientras que LLaMA 3.2 3B F16 demanda ~6 GB (mejor usarla en Macs de 32 GB o superiores, o en cuantizado).
Casos de uso: debido a su enfoque en eficiencia, son ideales para asistentes personales en dispositivos, chatbots integrados en apps móviles o IoT, y tareas de generación de texto cortas y rápidas. También se usan para soporte de código (explicación y generación) a pequeña escala, y por su licencia abierta pueden incorporarse en entornos empresariales con pocas restricciones. -
Phi (Phi-4 de Microsoft): Phi-4 es un modelo de Microsoft de ~14 mil millones de parámetros, parte de la familia Phi de modelos pequeños pero potentes. Ventajas técnicas: Sorprendentemente capaz en tareas de razonamiento lógico y código, alcanzando rendimientos cercanos a modelos mucho más grandes en dichas áreas. Phi-4 se ha entrenado con mezcla de datos sintéticos y supervisión para alinearlo bien con instrucciones y con fuertes salvaguardas de seguridad. Tiene una ventana de contexto de 16k tokens, suficiente para conversaciones moderadas o análisis de documentos medianos. Requisitos: Al ser 14B, en formato cuantizado Q4_K_M ocupa ~9.1 GB. Esto significa que en una Mac con 16 GB de RAM un modelo Phi-4 cuantizado podría correr, pero es más cómodo en una de 32 GB (o usando paginación a RAM).
Casos de uso: Excelente opción para entornos con recursos moderados que requieran capacidad de razonamiento paso a paso o generación de código. Por ejemplo, asistentes para depuración de código, agentes que resuelven problemas lógicos o matemáticos, etc. También es apropiado para investigación de small LMs, ya que Microsoft lo libera con licencia MIT facilitando su uso comercial. Dado su menor sesgo hacia creatividad, quizá no es el mejor para tareas creativas o conversacionales abiertas (según reportes de usuarios) y se recomienda enfocarlo a lógica y respuestas precisas. - Mistral (7B) y Mistral NeMo (12B): Mistral AI introdujo en 2023 un modelo de 7 mil millones de parámetros muy potente, y en colaboración con NVIDIA crearon Mistral NeMo 12B (Instruct 2407). Ventajas técnicas: El modelo de 7B de Mistral destaca por su velocidad y sorprendente capacidad en razonamiento, código y matemática dado su tamaño. Es ligero, ideal para aplicaciones en dispositivos con poca memoria. Por su parte, Mistral NeMo 12B ofrece una ventana de contexto ampliada a 128k tokens, situándose entre los modelos de 12B más avanzados. Además, mantiene estado del arte en conocimiento del mundo y precisión multilingüe en su tamaño. Requisitos: Mistral 7B cuantizado (Q4) puede rondar ~4 GB, apto incluso para GPUs de 8 GB. Mistral NeMo 12B en cuantización Q4_0 ocupa ~7.1 GB, por lo que se ejecuta cómodamente en Macs de 16 GB (utilizando casi la totalidad de la VRAM). Casos de uso: El modelo de 7B es ideal para aplicaciones en tiempo real donde se necesita respuesta rápida con recursos limitados (ej: asistentes en smartphones o en el navegador). El de 12B, con 128k de contexto, es perfecto para procesar documentos largos, chats extensos, o contextos como análisis de logs, conversaciones de servicio al cliente con historial largo, etc. Por ejemplo, se podría cargar un documento extenso o varias páginas de texto como prompt y solicitar un resumen o conclusiones, algo que 128k tokens permiten. Además, Mistral NeMo está pensado para ser reemplazo directo de Mistral 7B en sistemas existentes, ofreciendo mejor rendimiento sin cambiar arquitectura. Ambos modelos están bajo licencia Apache 2.0, facilitando su uso comercial.
-
Gemma 3 (Google): Gemma 3 es parte de la familia de modelos basados en la tecnología Google Gemini, presentados como modelos ligeros y eficientes. Ventajas técnicas: Todos los Gemma 3 son multimodales (pueden procesar texto e imágenes) y tienen contextos muy amplios (hasta 128k tokens en los de mayor tamaño). Soportan más de 140 idiomas, incluyendo español, inglés y muchos más, por lo que son altamente multilingües. Vienen en cuatro tamaños: 1B, 4B, 12B y 27B de parámetros. A pesar de ser “compactos” comparados con gigantes propietarios, exhiben muy buen desempeño en QA, resumen y razonamiento, según Google.
Requisitos: Gemma 3 1B es extremadamente liviano (815 MB cuantizado) y corre en prácticamente cualquier dispositivo. El de 4B pesa ~3.3 GB cuantizado, también fácil de manejar en Mac 8-16 GB. El de 12B ~8 GB y el mayor de 27B ~17 GB (estos ya requieren 16-32 GB de RAM para estar cómodos). Cabe destacar que el de 27B es quizás el modelo más grande que se puede intentar ejecutar en un solo GPU de gama alta o en una Mac Studio con suficiente memoria (su nombre clave es “el modelo más capaz que corre en una sola GPU” según la biblioteca de Ollama). Casos de uso: Gemma 3 es muy versátil; sus desarrolladores destacan su uso en chat conversacional y asistentes generales (por su entrenamiento multimodal y amplio contexto, puede mantener conversaciones largas y referirse a imágenes dadas). Por ejemplo, es idóneo para construir un chatbot que pueda analizar imágenes adjuntas por el usuario o referenciar un diagrama. También es útil para resumir documentos largos (gracias al contexto de 128k en versiones 4B+), y para aplicaciones multilingües globales, dado su soporte robusto a muchos idiomas. En resumen, Gemma combina amplio contexto + multimodalidad + eficiencia, haciéndolo atractivo para aplicaciones ricas en contenido. -
Qwen 2.5 (Alibaba Cloud): Qwen 2.5 es la serie de modelos open-source de Alibaba, sucesora de Qwen (también conocido como Alibaba Tongyi Qianwen). Ventajas técnicas: Qwen2.5 destaca por soporte multilingüe amplio (más de 29 idiomas) y una ventana de contexto de 128k tokens por defecto, con variantes extendidas hasta 1 millón de tokens en investigación. Esto la posiciona como una de las familias con mayor contexto del mercado. Además, Qwen ha incorporado mejoras para formato JSON nativo y uso de herramientas, pensando en integraciones más directas con sistemas que requieran respuestas estructuradas. Hay múltiples tamaños de modelo disponibles: desde versiones pequeñas (p.ej. 0.5B, 1.5B parámetros) orientadas a dispositivos muy limitados, pasando por 7B, 14B (los más comunes para local), hasta modelos masivos de 32B y 72B parámetros
github.com.
Requisitos: Las versiones pequeñas de Qwen2.5 (<=7B) se pueden ejecutar en hardware modesto (una 7B cuantizada ~4-5 GB de VRAM). La 14B requerirá ~8-10 GB, similar a Phi-4. Los modelos gigantes (32B, 72B) exceden lo que un Mac típico puede manejar, y están más pensados para entornos de servidor con GPUs de 40GB o más. Por ejemplo, la imagen Docker de un Qwen2.5-72B indicaba 114 GB de tamaño, impráctico para uso en Model Runner estándar. Casos de uso: Qwen2.5 de 7B o 14B son excelentes para aplicaciones bilingües chino-inglés (fueron entrenados intensivamente en chino, pero también en inglés y otros idiomas), como asistentes empresariales en regiones donde se requiere ese soporte. También son útiles en tareas de conversación de largo contexto, chatbots de soporte que pueden mantener historial extenso (por ejemplo, conversaciones de soporte técnico que duran muchas interacciones). Las versiones de 0.5B-1.5B podrían utilizarse en dispositivos muy limitados o para pruebas de concepto rápidas. En general, Qwen 2.5 es una actualización versátil con mejor comprensión lingüística y amplio contexto, adecuada para casos en que se necesite integrar la IA localmente en diferentes idiomas o manejar entradas muy largas.
Tabla comparativa de modelos soportados:

Notas: Los tamaños listados son aproximados para modelos cuantizados de referencia. Los valores exactos pueden variar según la cuantización utilizada y formato (GGUF, etc.). La ventana de contexto puede depender de la versión/quantización; se indica la máxima soportada en cada caso.
En conclusión, Docker Model Runner soporta una gama de modelos punteros que cubren desde necesidades de eficiencia y bajo recurso (SmolLM, LLaMA 3.2), hasta modelos de razonamiento avanzado (Phi-4, Mistral) y capacidades de contexto extenso y multilingües (Gemma, Qwen). Cada uno ofrece ventajas técnicas únicas que permiten al desarrollador elegir el modelo adecuado según el caso de uso: por ejemplo, un chatbot multilingüe largo podría usar Qwen2.5 o Gemma, un asistente de programación usar Phi-4 o Mistral 7B, y una aplicación móvil offline usar LLaMA 3.2 de 1B. La integración vía Docker hace que probar distintos modelos sea tan sencillo como hacer docker model pull del nuevo modelo y cambiar una variable de entorno, lo cual acelera la experimentación y adopción de estos LLMs en proyectos reales.
Fuentes: Se han utilizado documentación oficial de Docker, publicaciones técnicas de Docker Captains, así como las tarjetas de modelo proporcionadas por Docker y los repositorios de los proyectos Ollama/OEM (Google, Microsoft, etc.) para asegurar la veracidad de las características mencionadas. Cada cita en el texto corresponde a la fuente específica donde se corroboró la información. Así, este informe técnico ofrece una visión clara y fundamentada para decidir entre Docker Model Runner y Ollama, junto con las instrucciones prácticas y consideraciones para su uso efectivo en desarrollo.
🧠 IA y Modelos Generativos
#IA #InteligenciaArtificial #LLM #ModelosDeLenguaje #MachineLearning #DeepLearning #AI #GenerativeAI #AItools #IAopensource #Transformers #NeuralNetworks #TextGeneration #LanguageModels #OpenSourceAI #LLMsLocales #AIGenerativa #NLP #AIprivacy #InferenciaLocal #LLMlocal #AIdev #ModelosLLM #ModelosIA #IAenLocal #LLMoffline #LLMprivate #AIonEdge #AIInference #AIoffline #MultiLanguageLLM #ChatbotsIA #AIengine
🐳 Docker & Contenedores
#Docker #DockerModelRunner #Contenedores #DevContainers #DockerDesktop #DockerHub #OCI #DockerCI #DockerCompose #DockerTips #DockerTools #InfraestructuraComoCódigo #InfraestructuraVersionable #InfraestructuraIA #InfraAsCode #Containers #InfraestructurasIA #DockerBeta #ModelosEnDocker #ContenedoresIA #DockerML #DockerAI #DockerGPU #ContenedoresInteligentes #AIinContainers #ContainerizedAI #RunLLMwithDocker #DockerPull #DockerRun #DockerApps #DockerModels #DockerDevelopment
⚙️ Desarrollo, DevOps y CI/CD
#DevOps #CICD #PipelineIA #FlujoDeTrabajoIA #FlujosCI #CIforAI #DesarrolloIA #DesarrolloLocal #IntegracionContinua #DeployIA #DevEnIA #LocalAI #AIstack #BuildWithDocker #InfraestructurasIA #DeveloperTools #HerramientasDesarrollo #MLOps #LLMDev #BackendDev #AIBackend #AIendpoint #OpenAICOMpatible #OpenAIAPI #DesarrolloBackendIA #IntegraciónLLM #DevSecOps #TestAutomatizados #InfraestructuraReproducible #AutoInfraestructura #ReproducibilidadIA
💻 Tecnología en Apple Silicon y Windows
#AppleSilicon #MacM1 #MacM2 #MacM3 #MacM4 #GPUApple #MPS #MetalApple #AceleraciónML #AceleracionGPU #AIonMac #ModelRunnerMac #DockerMac #IAenMac #IAenM1 #DockerGPU #TensorAcceleration #MacDev #ModelosEnMac #NVIDIAWindows #CUDAWindows #WindowsLLM #GPULocal #ModelRunnerWindows
🔐 Privacidad, Seguridad y Alternativas a la Nube
#PrivacidadIA #SinNube #OfflineAI #AIlocal #PrivacidadDigital #IAenLocal #ModelosSinNube #ZeroAPI #AntiOpenAI #NoCloudAI #LLMSeguro #AIprivado #SelfHostedAI #IAempresarial #SoberaníaDigital #ComplianceIA #GDPRAI #AirGappedAI #SecurityFirstAI #IAética #DataSovereignty
📚 Comparativas y herramientas
#ComparativaIA #DockerVsOllama #ModelosComparados #HerramientasLLM #MejorLLM #LLMComparativa #LocalVsCloud #BattleOfLLMs #AIShowdown #ModelRunnerVsOllama #LLMtools #AIstack #ComparaciónTecnológica #InfraestructuraIA #DevToolComparison #DockerVs #TechTools
🚀 Casos de uso y Aplicaciones
#ChatbotsLocal #AsistentesIA #Summarization #QnA #AnálisisTexto #IntegraciónIA #BackendLLM #PrototipadoIA #ChatPrivado #DevAssistants #IAcorporativa #IAparaEmpresas #AIinDev #ProductividadIA #DocsInteligentes #DashboardsIA #AgentsIA #LLMAssistant #AIforDocs #CodeGenerationAI #IAparaDesarrolladores #LocalDevIA #PromptEngineering #AGIlocal #EdgeComputingAI
📣 Difusión y comunidad
#QuantumSec #QuantumSecIA #QuantumLabs #OpenSource #HypeIA #IARevolucion #NovedadesIA #IA2025 #TrendingAI #NoticiasTech #ExploraLLM #AIRevolution #IAenEspañol #AIenEspañol #ComunidadTech #DockerCommunity #IAdeveloper #AIExplorers #AIhispano #Tech2025
